
近期,国内两大模型先后更新:讯飞星火V3.5发布春季上新版,支持长文本、长图文、长语音、多情感超拟人合成和一句话声音复刻,同时首发星火图文识别大模型,能够快速识别和学习多类型海量知识,使得行业场景下的回答更加专业和精准;
商汤日日新大模型迭代到5.0,在语言、知识、推理、数学、代码等领域的能力有明显提升,同时支持多模态,可快速处理处理文档、图表、截图和照片中的内容。
这两款大模型整体表现如何?今天我们将站在普通用户角度,分别对两款大模型的语义理解、逻辑推理、知识问答、多模态和长文本等5大能力进行评测。
一、语义理解
语义理解是一种让计算机理解和处理自然语言文本的技术,可以帮助机器更准确地反映人类意图,实现人机交互的智能化。具备良好语义理解的大模型能够更准确地理解人类语言的含义和上下文信息,从而进行相关的推理和判断。
为了评估这两款大模型的语义理解能力,我们将从语言理解、总结提练和抗干扰水平三个方面进行测试。
1、理解能力
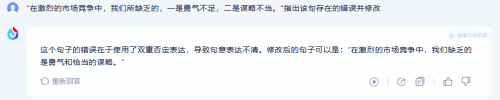
测试题1:“秋天的北京是美丽的季节”指出这个句子的错误,并修改。
该句的主要毛病在于主宾搭配不当,北京是地名而非季节。
商汤商量没有找出句中的错误,认为该句是正确的。

讯飞星火找出了其中错误并给出了正确修改。

那么,两大模型的这一表现是否是偶然的呢?为了弄清这一问题,我们继续为其提供了另一个病句并令其修改:“在激烈的市场竞争中,我们所缺乏的,一是勇气不足,二是谋略不当。”
商汤商量仍然认为没有问题。
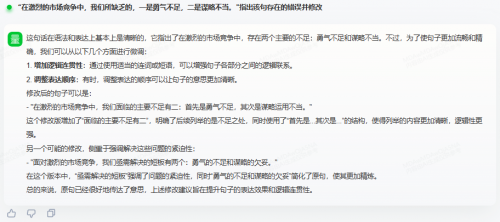
讯飞星火依然一针见血,找出了问题并进行了修改。
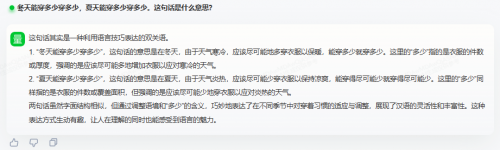
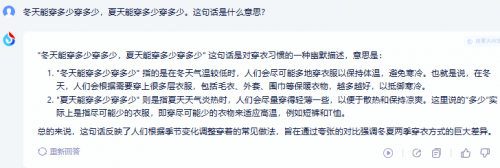
测试题2:冬天能穿多少穿多少,夏天能穿多少穿多少。这句话是什么意思?
两大模型的都给出了较令人满意的回答。
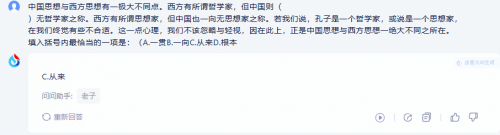
测试题3:中国思想与西方思想有一极大不同点。西方有所谓哲学家,但中国则( )无哲学家之称。西方有所谓思想家,但中国也一向无思想家之称。若我们说,孔子是一个哲学家,或说是一个思想家,在我们终觉有些不合适。这一点心理,我们不该忽略与轻视,因在此上,正是中国思想与西方思想一绝大不同之所在。 填入括号内最恰当的一项是:A.一贯;B.一向;C.从来;D.根本
该题来自2021年某省省考,旨在考察考生的言语理解和表达能力。就句意来说,选B、C、D似乎都行,但如果根据后文的“但中国也一向无思想家之称。”应该选“B:一向”。
这个问题,商汤商量选择了弃权,称“不了解相关信息。”讯飞星火选择了“C:从来”(讯飞选择的答案和笔者及周围几个同事相同,老实说,对于这个题,应该真正答对的可能不多)。

2、总结提炼
对文段的总结提炼被认为是考察大模型是否快、准、狠的重要因素,我们做了以下测试:
测试1:总结新闻主题。
商汤商量再中结舌咒,称:“不了解相关信息”。讯飞星火的总结简洁而准确。


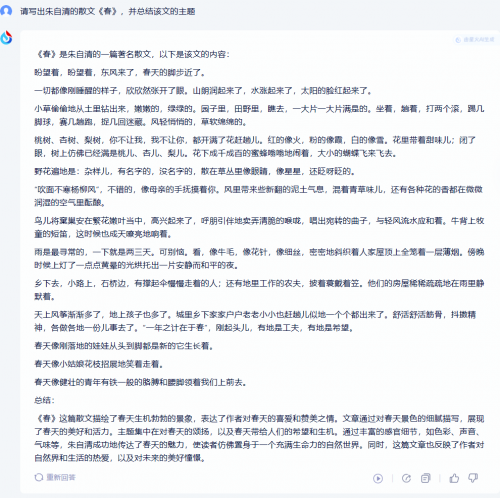
测试题2:总结文章主题。“请写出朱自清的散文《春》,并总结该文的主题”
商汤商量表示“由于篇幅限制,我无法在这里全文复现这篇散文。但我可以提供一个简短的概述,并总结其主题”,总结内容略显臃肿。讯飞给出了全文,总结内容精练、准确。

3、抗干扰能力
抗干扰项能力是考察大模型是否足够“聪明”的重要手段,我们在这项考察上挖了坑,其实给出的问题和前面两个半句并没有联系,看看他们的回答:
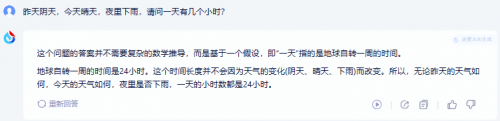
测试题1:昨天阴天,今天晴天,夜里下雨,请问一天有几个小时?
两大模型都完美避坑,给出了正确答案。

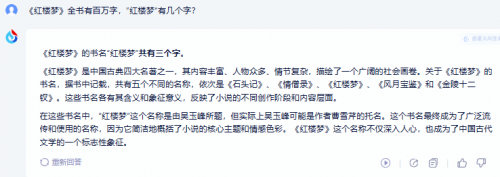
测试题2:《红楼梦》全书有百万字,“红楼梦”有几个字?
回答同样完美。值得一提的是讯飞在回答完基本问题后,还介绍了“红楼梦”书名渊源,有助于拓展知识。

二、逻辑推理
推理是人类智能的基本要素,在问题解决、决策制定和批判性思维等活动中发挥着关键作用,同样它也是考验大模型智力水平的一个重要标准。
这里,我们将从数学计算、类比推理和连续推理三个个方面入手,评估两款大模型的逻辑推理能力。
1、数学推理
测试题1:5名学生参加某学科竞赛,共得91分,已知每人得分均为整数且各不相同,其中最高分是21分,则最低分最低是多少?
这是一道典型的通过最高值求最低数的问题,要使最低分得分最低,其他人得到的分数应该尽可能的高。已知最高分为21分,且得分各不相同均为整数,那么其他人依次应为20、19、18、n,则n=91-21-20-19-18=91-78=13分。故正确答案为C。
对于该问题,商汤商量脑洞大开,数学家风范尽显,给出了一长串复杂算式,看着高深莫测,实际上给出的结果是错误的。讯飞星火回答正确,思路清晰。


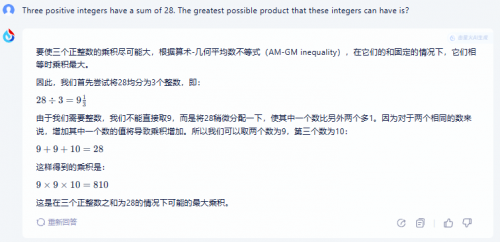
测试题2:Three positive integers have a sum of 28. The greatest possible product that these integers can have is?
这是一道小升初奥数题,成人看起来并不难,但由于是英文,估计大多数人都会发蒙,翻译成中文是“三个正整数的和为28。这些整数可能的最大乘积是多少?”,这道题考验的主要是两大模型是英文识别及理解能力。正确的答案是810。
商汤商量谢绝回答,表示“暂不支持该种语言噢!我擅长中文。”,讯飞解答正确并给出了通俗易懂的解题思路。
2、类比推理
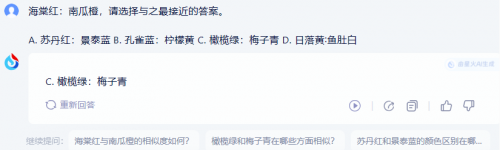
测试题1:海棠红:南瓜橙,请选择与之最接近的答案。A.苏丹红:景泰蓝 B. 孔雀蓝:柠檬黄 C. 橄榄绿:梅子青 D. 日落黄∶鱼肚白
这是国考中的题目,知乎上对该题目的点评是:类比推理字数少得很,难度很惊人。
解答该题的关键是要抓住题干“海棠红:南瓜橙”的两大特点,一是它们描述的都是颜色,属于并列关系;二是海棠和南瓜者都是植物。只有抓住这两大特点,才能看出正确答案是C,那么商汤商量和讯飞星火能否顺利过关呢?
商汤商量再次顺利栽倒,选择了B。而讯飞星火虽然给出了正确答案,却没有给出理由,学霸的魅力大打折扣。

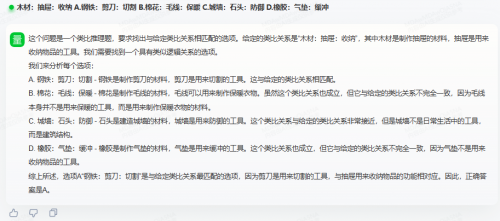
测试题2:木材:抽屉:收纳;A.钢铁:剪刀:切割;B.棉花:毛线:保暖;C.城墙:石头:防御;D.橡胶:气垫:缓冲
这个问题和前面问题相似,题干中抽屉是由木材构成的具有收纳功能的器物,所以与之最接近的答案是D,气垫是由橡胶构成的具有缓冲作用的物品。
至于选项A,看似和题干相符,但其实个陷阱,剪刀虽然是由钢铁制造的,但其主要功能是裁剪而非切割,很多人会因为忽视切割和裁剪的区别而选择该项。商汤商量也不例外。

相比之下,讯飞星火依然表现良好,虽然同样只给出了答案,而没有给出解释。
3、连续推理
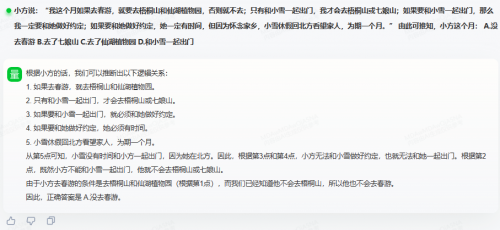
测试题1:小方说:“我这个月如果去春游,就要去梧桐山和仙湖植物园,否则就不去;只有和小雪一起出门,我才会去梧桐山或七娘山;如果要和小雪一起出门,那么我一定要和她做好约定;如果要和她做好约定,她一定有时间,但因为怀念家乡,小雪休假回北方看望家人,为期一个月。”
由此可推知,小方这个月:A.没去春游;B.去了七娘山;C.去了仙湖植物园;D.和小雪一起出门
正确答案是“A.没去春游”,两大模型都给出了正确答案,并给出了推理过程。
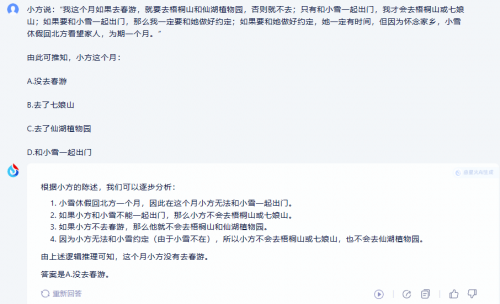
测试题2:有三顶红帽子和两顶蓝帽子。将五顶中的三顶帽子分别戴在A、B、C三人头上。这三人每人都只能看见其他两人头上的帽子,但看不见自己头上的帽子,并且也不知道剩余的两顶帽子的颜色。 问A:"你戴的是什么颜色的帽子?" A说:"不知道。" 问B:"你戴的是什么颜色的帽子?" B想了想之后,也说:"不知道。" 最后问C。C回答说:"我知道我戴的帽子是什么颜色了。" 当然,C是在听了A、B的回答之后而作出推断的。试问:C戴的是什么颜色的帽子?
两大模型同样给出了正确答案。

三、知识问答
知识问答是一种考察大模型能力的有效方式之一。通过知识问答,可以测试大模型对于问题的理解和回答的准确性、完整性和连贯性。
该环节我们将通过与生活、地理、历史有关的三个问题考验两大模型的知识能力。
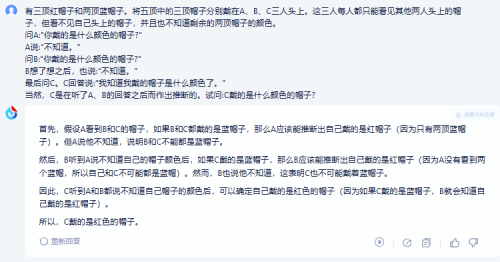
测试题1: 关于生活常识,下列说法不正确的是:A.为了延长灯丝的寿命,在电灯泡中充入氮、氢等惰性气体;B.朱砂是甘汞的天然矿石,可制成颜料;c.扇子与电风扇的降温原理相同,均是加速空气流动使人身上的汗液蒸发加快,从而带走热量;D.荧光笔与荧光棒的荧光原理相同,均能在夜间发光。
正确答案:D。
两大模型回答正确。

测试题2:钓鱼岛是我国领土不可分割的一部分,按岛屿的成因分类,它属于:A.大陆岛B.冲积岛c.珊瑚岛D.火山岛
正确答案是A。
两大模型回答正确。商汤商量一如既往地给出了解释,值得表扬。

测试题3:有人说孔子不姓孔,屈原不姓屈,这是真的么
该题的答案是真的,其实孔子姓子氏孔,屈原姓芈氏屈。这个问题牵涉到中国古代姓氏概念,估计现在有很多人不知道。好在两大模型知识渊博,都给出了正确答案,同时也给出的相应解释,感兴趣的朋友可以看一看。

四、多模态
多模态能力是指在处理和理解文本、图像、语音、视频等多种形式的数据时所具备的能力。具备多模态能力的大模型可以更好地理解和处理各种类型的数据,从而提高其性能和泛化能力。
1、图片解读
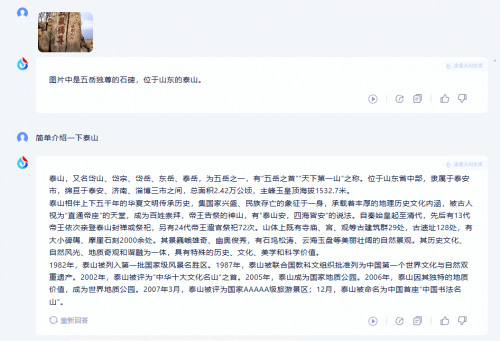
测试图1:

商汤商量识别出了与图片相关的地点是泰山,并对泰山作了介绍,但并未解释图片本身信息。讯飞识别出了图片主体是“五岳独尊的石碑,位于泰山”,其回答简单明了,让人满意。

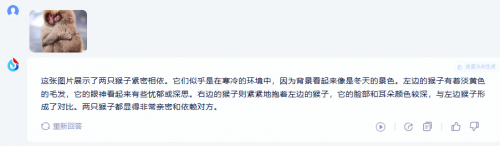
测试图2:

两大模型都对图片内容给出了较为贴合的描述。

2、图片生成
所谓图片生成,即让大模型根据使用者的语音或文字指令,生成符合要求的图片,就是我们熟知的AI作画。
测试题:根据下面要求画一幅画,夕阳下,一位牧羊老人走在山路上,旁边是羊群,时间是春天。
由于商汤商量不支持AI作画,所以只给出了绘画建议,也正是基于此,我们对这一环节的评测就此结束。讯飞星火则根据要求,很好地完成了作业。


3、音频生成
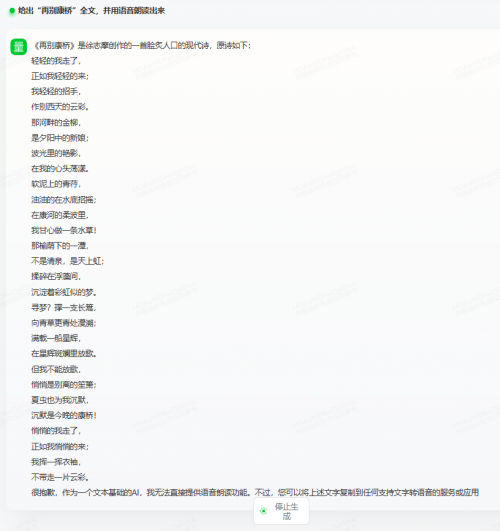
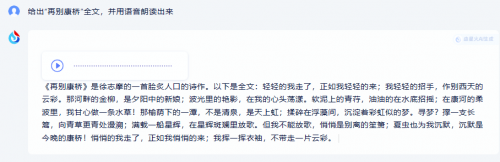
测试题:给出“再别康桥”全文,并用语音朗读出来。
商汤商量给出了全文,但不具备生成音频及朗读功能;讯飞星火给出了全文,同时生成了音频,通过点击即可实现朗读。
4、视频生成
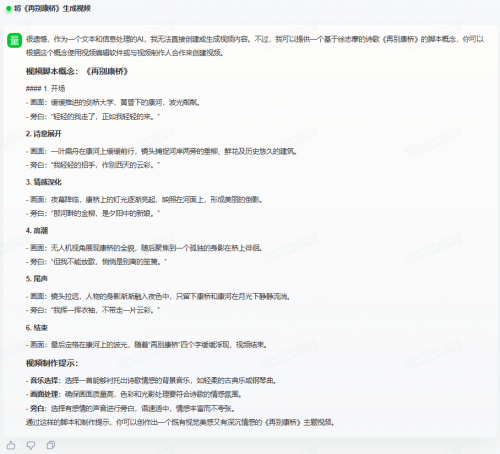
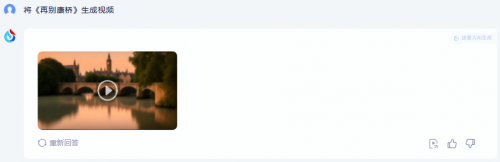
即根据输入的文字生成包含音频的视频,我们给出的题目是“将《再别康桥》生成视频”。商汤商量同样不具备该能力,只给出了拍摄建议。讯飞星火轻松完成。

五、长文本支持
长文本能力考验了大模型在自然语言处理领域的综合能力,包括理解、记忆、逻辑推理、生成、关联、注意力分配、语言表达和知识整合等多个方面,因此是大模型能力的综合体现。
大模型的长文本能力,除支持在聊天输入框中直接输入长文本,并令其实现相应回答外,还包括直接导入文档。
两者中,以直接导入文档最考验大模型对长文本的支持程度。为此我们设定的测试如下:
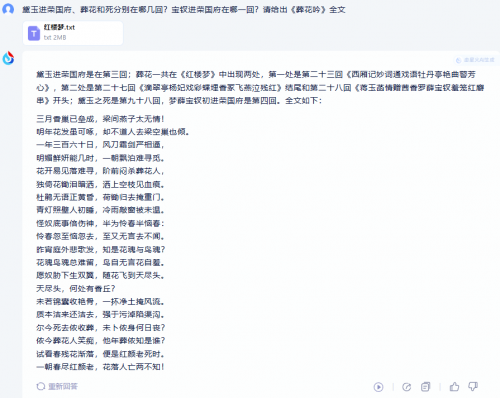
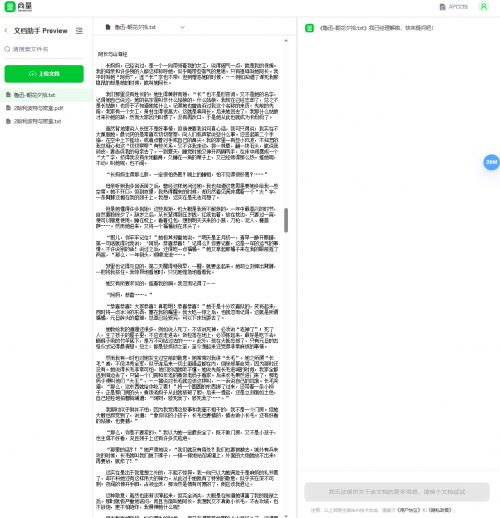
测试题1:上传《红楼梦》TXT电子书,让两大模型回答以下问题:“黛玉进荣国府、葬花和死分别在哪几回?宝钗进荣国府在哪一回?请给出《葬花吟》全文。”
商汤商量支持一次上传10个文件,单个文件大小不超过10MB,格式支持PDF、TXTDOC、EPUB和MOBI等,不知为何,却在上传大小为2.49MB的《红楼梦》TXT电子书时提示“解释失败”,试了几次都是如此。
讯飞星火则在接受文档后给出了答案,而且相当正确。
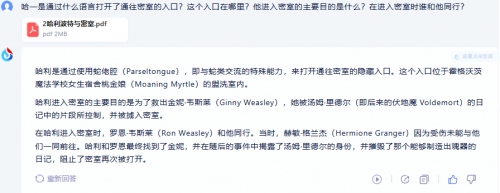
测试题2:上传《哈利波特与密室.pdf》,提出以下问题:“哈利是通过什么语言打开了通往密室的入口?这个入口在哪里?他进入密室的目的是什么?在进入密室里谁和他同行?”由于马虎,输入时误将“哈利”打成了“哈一”,不过讯飞星火仍然解读成功,并给出了不错的回答。商汤商量虽然上传成功,并将文档内容显示到了界面中,且提示“我已理解,快来提问吧”,但当我们真正提出问题后,却仍然没有回答,提示“我无法提供关于该文档的更多信息。”
商汤商量是不是因为上传的文件太大而导致解读失败(《红楼梦.txt》大小为2.49MB,《哈利波特与密室.pdf》为1.79MB)?为此我们又上传了大小为115KB的鲁迅的《朝花夕拾.txt》电子书,结果仍是可以上传却不能回答问题。
小结:
至此,对两大模型包括语义理解、逻辑推理、知识问答、多模态和长文本在内的等5大能力评测完毕。
从两大模型的表现来看,讯飞星火的优势十分明显,5大能力没有明显短板。同时也存在些许不足,比如在解答类比推理时,它往往只给出答案,而不给出理由,这让人怀疑它是不是蒙对的。
商汤商量明显不具备多模态能力,对长文本的支持也较为有限,这让它在当前短视频时代用户非常重视的图文、音、视频生成方面,极易被用户舍弃。